4 Case studies of real world eventsA number of key insights implied that continuously running, broad and top-level research did not reflect either how people use Twitter, or the best ways to analyse it. People did not in general express generic sentiment on Twitter about the EU. Our analytical method was also not well suited to produce an accurate picture of constant, rolling sentiment: specific topics changed and the way that people spoke about those topics also changed.Instead, Twitter was found to be fundamentally a reactive medium. A tweet is overwhelmingly a reaction to an event that the tweeter has otherwise encountered – either online or offline, whether through reading mainstream media or being told about it by a friend. Twitter use fits into how a person engages with the world as they learn about it from a much wider ecology of different currents of information. In this chapter we examine how Twitter responded to real-time events through a series of case studies.
An attitude expressed on Twitter is usually a social gloss, a non-neutral piece of commentary about a specific event. A body of tweets is really a snapshot mosaic of opinions from people who have been spurred to react to something they have read about, either in the news or on Twitter, and almost always something that has happened, either online or offline. Sentiment-bearing tweets therefore are almost always anchored in the context of important events that prompt discussion, and the mainstream media environment that reports on them.What we are witnessing is the reaction of ordinary people to events as they unfold – so-called ‘twitcidents’ – a digital annotation of an important event. A complex, varied and evolving storm of reaction on Twitter is a new kind of aftermath to events of significance – an online shadow of interpretations, condemnations, jokes, rumours and insults.
The opportunity to learn about attitudes from these kinds of data is not in any sense to learn about them as generic or general. The opportunity is to identify and analyse these twitcidents as bodies of a specific kind of reactive sentiment expressed within a specific context. Only from this very event-specific context would it be possible carefully to begin to infer the more general or fundamental attitudes that this specific reaction implies. This is in line with the optimal performance of the technology we developed – specific conversations in specific contexts with specific ways of using language to express meaning.
An event-specific method of analysis was developed along the following lines:
• Identify surge in relevant Twitter traffic.
• Describe the contours of the surge: Identify when it began, how it evolved and when it ended.
• Determine the cause and topic of the surge: Understand what the tweets included in the surge are talking about, and the broader context within which they are made. Qualitative dips were taken into the tweets located at one or a number of points during the surge, analysing information about the tweets – such as what links they were sharing, and what #tags they contained, and also to build a picture of the backdrop against which the surge occurred – what offline events were occurring at the time – a relevant speech by a EU politician – and whether the media was reporting an important and related news story.
• Determine event-driven attitudes: Only now, with a developed understanding of the context within which people use Twitter, is it possible to infer people’s attitudes towards EU institutions. This was done through moving carefully (where possible) through three stages: unstructured, qualitative analysis of randomly selected tweets to suggest broad distinctions present in the data; manual structured coding of randomly selected tweets to formalise and measure these distinctions; and the training of a bespoke automated classifier to make this distinction for all the tweets that were part of the surge.
• Draw out wider, more general insights: From this very specific, contextualised, event-driven analysis, wider insights can be drawn, including how different twitcidents relate to each other, and how different language groups react to a common story, event or controversy.
To make, test and demonstrate this way of understanding Twitter, we undertook a number of case studies using digital observation. [52] Surges of Twitter traffic in one or more of our streams were identified. For each, we applied a mix of qualitative and quantitative methods to provide an idea of the context and content of the twitcident. Overall, this method was tested to see how far listening to the tweeted reaction surrounding an event can provide a useful and meaningful insight into citizens’ attitudes about these events, and then more broadly the themes these events relate to.
Case study 1: Cyprus bailoutThe 2012–13 Cypriot financial crisis involved the exposure of Cypriot banks to overleveraged local property companies, the Greek debt crisis (Cypriot banks had made loans to Greek borrowers that were worth 160 per cent of the island’s GDP), the downgrading of the Cypriot Government to junk status by international rating agencies, the consequential inability to refund its state expenses from the international markets, and the reluctance of the Cypriot Government to restructure Cyprus’ troubled financial sector. On 16 March 2013, Cyprus became the fifth nation (after Greece, Ireland, Portugal and Spain) to get a Eurozone bailout as the Eurogroup, European Commission, European Central Bank and International Monetary Fund agreed on a €10 billion bailout with Cyprus to recapitalise its ailing banking system in return for a series of drastic measures which would hit the country’s depositors.
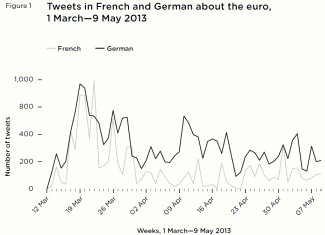 Figure 1 Tweets in French and German about the euro, 1 March—9 May 2013
Figure 1 Tweets in French and German about the euro, 1 March—9 May 2013From 16 March to 19 March 2013, the number of tweets in French and German about the ‘euro’ spiked dramatically (figure 1).
16–17 March 2013: bailout announcementOn the morning of 16 March 2013 the French newspaper Libération ran with the headline ‘Dix milliards d’euros pour sauver Chypre’ (‘Ten billion euros to save Cyprus’); Le Figaro had ‘Chypre: un sauvetage inédit à 10 milliards d’euros’ (‘Cyprus: an unusual 10 billion euros rescue’) and Le Monde, ‘A Chypre, la population sous le choc, le président justifie les sacrifices’ (‘In Cyprus, people in shock, the president justifies the sacrifices’). [53] In Germany, Der Spiegel announced, ‘Hitting the savers: Eurozone reaches deal on Cyprus bailout’. [54]
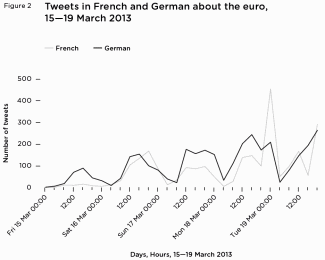 Figure 2 Tweets in French and German about the euro, 15—19 March 2013
Figure 2 Tweets in French and German about the euro, 15—19 March 2013Immediately following the news, the number of French and German euro streams surged. The greatest number of conversations happened between midday and 6pm every day, building up to higher and higher peaks of traffic. German conversations consistently built up peaks of conversation between 12pm and 6pm every day: 116 on 15 March, 214 on 16 March, 257 on 17 March, 329 on 18 March, dipping on 19 March to 299 and climbing on 20 March to 380. French conversations were less consistent, with a high peak of 516 between 6pm on 18 March and midnight on 19 March (figure 2).
Using randomly drawn qualitative dips of 100 tweets on these days, we found the French and German conversations about the euro were dominated by conversations about the Eurozone, especially Cyprus. Around 90 per cent of tweets in French were about Cyprus – 87 per cent actually contained the word ‘Chypre’ – Cyprus – and 30 per cent used the #cyprus hashtag; 70 per cent of tweets in German were specifically about Cyprus, and an additional 26 per cent of tweets were about the Eurozone crisis as a whole. In contrast, the day before – 15 March 2013 – just 12 of 100 randomly selected relevant tweets about the euro referred to the Cypriot banking crisis.
At this early stage of the twitcident, tweets in German and French overwhelmingly just shared the information that the bailout had been agreed. [55] However, attitudes related to the Cypriot bailout were soon expressed more frequently. In French tweets at around noon on 16 March, people started sharing more negative attitudinal headlines (‘Cyprus in shock after bailout plan’, ‘Cyprus: does the Eurozone still exist?’), though without any explicit comments. Later that day, and the next, people started posting attitudinal remarks of their own about savers’ bank accounts being ‘plundered’ by an ‘arbitrary tax’, indicating that this detail of the bailout agreement had started to become more widely known.
On 17 March, Die Welt took the firm editorial line: ‘Zypern schröpft die Sparer’ (‘Cyprus fleeces savers’). Echoing this, many German speakers seemed to be in solidarity with Cyprus savers, implying that the use of individuals’ savings is unfair and anti-democratic. However, plenty of users were not in favour of a bailout, and criticised the amount paid by other citizens of the Eurozone. A very significant number predicted or called for the end of the euro. Some people mentioned the comparative strength of the deutschmark.
19 March: demonstrationsAgainst the background of large demonstrations outside the House of Representatives in Nicosia by Cypriots protesting at the bank deposit levy, the number of German (927) and French (853) tweets about the euro reached a peak. Again, nearly all were to do with the bailout and Cyprus: 94 per cent of tweets in French were about the bailout, 56 per cent of tweets in German were about the story, with the remainder talking about the euro crisis more broadly. Many German tweeters expressed concern that Cyprus had refused the terms of the bailout, and said that other alternatives were unconvincing. Some called for Cyprus to leave the Eurozone rather than be bailed out. French tweeters were more neutral, sharing news stories as the situation developed, especially after the 5pm announcement that Cyprus had rejected the terms of the bailout. Those French tweeters who did express attitudes usually did so by expressing solidarity with Cyprus’ rejection of the ECB-imposed levy.
21 March: plan BIn the wake of the rejection of the terms of the bailout, Cypriot politicians tabled seven ‘plan B’ bills to parliament. As protestors clashed with riot police outside parliament, the European Central Bank piled the pressure on Cyprus by warning it would cut off its emergency liquidity assistance after 25 March unless an EU–IMF programme was in place.
The volume of French and German conversations about the euro remained high on 21 March – 1,000 in French, and 669 in German. Nearly all (98 per cent) of the tweets in French were about the situation in Cyprus (82 per cent still used the word ‘Chypre’), although the tweets in German became more general – 36 per cent were about the Cypriot banking crisis, but discussion was turning more generally to the euro and the Eurozone.
The tweets in French focused on the ultimatum put to Cyprus by the European Central Bank. Most tweets simply shared news stories and headlines. Of the few that expressed attitudes, all were negative, saying that the European Central Bank had ‘declared war on a European country’, and that the move was ‘an act of war under international law’. By mid-afternoon, the story that it was now a real possibility that Cyprus might leave the Eurozone broke, and a negative headline stating that the ECB was proposing to ‘strangle’ Cyprus was much shared. Later in the evening it was reported that Cyprus was working on a plan B, and that the EU was ready to discuss it. Similar to the tweets in French, German tweeters principally used Twitter to keep track of the fast changing events. Most simply shared links to articles reporting neutrally on the changing situation. Several tweeted the statement, ‘Euro-Retter meinen, die Situation auf Zypern sei emotionsgeladen! Vielleicht merken sie auch noch das die ganze Euro Zone geladen ist!’ (‘Ministers proposing a bailout think that emotions are running high in Cyprus. Perhaps they will notice that the entire Eurozone is hopping mad!’) The anti-euro sentiment in the German data set continued: some tweets linked to an article about Germans’ wish to return to the deutschmark.
24 March: bailout terms agreedBy 24 March, discussions of the ‘euro’ in both languages had begun to decline (there were only 466 in German and 249 in German that day). However, they spiked again on 25 March (722 tweets in German and 645 in French) with the news that an eleventh-hour deal for a 10 billion euro bailout was agreed between the Cyprus Government and the Troika, which safeguarded small savers while inflicting heavy losses on uninsured depositors (including many wealthy Russians using Cyprus as a tax haven). That day it had been decided that deposits up to €100,000 would be protected, but that any holdings larger than this would suffer a ‘haircut’ of up to 40 per cent. The revised agreement, expected to raise €4.2 billion in return for the €10 billion bailout, did not require any further approval of the Cypriot parliament.
Almost all (99 per cent of) tweets in French and over half of tweets in German were about Cyprus (with the other half referring to the Eurozone crisis more generally).
In France, nearly all tweets shared headlines, quite a number of them attitudinal but with no express endorsement or comment by the poster. The deal would have ‘heavy social consequences’ according to one much-shared article, but another claimed that the deal ‘brings an end to the uncertainties facing Cyprus and the Eurozone’. Some noted how the markets had reacted with relief to the agreement. Another much-shared article later in the day announced that Cyprus staying in the Eurozone was still not guaranteed. The last-minute bailout of Cypriot banks was the main topic of the news for German language tweeters, in particular the consequence of the bailout on Germany’s relationship with the rest of the Eurozone; 54 out of 100 randomly selected tweets referred specifically to the Cypriot bank bailout, with the other 46 referring to the Eurozone crisis more generally. Anger at the bailout was still in evidence. General dissatisfaction with the single currency began to replace the previous focus on Cyprus – many tweets mentioned the European crisis in more general terms without specifically referencing Cyprus. There were ‘harsh but fair’ calls for Germany to leave all the other countries. There was a call for the politicians responsible for the crisis to be jailed, and an ‘us against them’ sentiment: ‘So now Cyprus is saved. Who will save us from the saviours? #euro #merkel’.
29–30 March: the end of the crisisBy 29 March, volumes in relevant conversations about the euro in both languages had declined from their 25 March high. On 29 March there were 386 relevant conversations on the euro in French and 302 in German. The tweets in French continued to discuss Cyprus (half of the sampled tweets shared an article from Le Monde reporting that the Cypriot president assured people that Cyprus would stay in the Eurozone). From the morning onwards, another much repeated tweet was the headline ‘Let’s make the fiscal paradises jump’. In German, there was significantly less discussion about the Cyprus issue. High-levels of anti-euro sentiment continued throughout a more topically varied and general discussion, with one of the most shared stories an article looking at the facts behind a claim that Germans have less money than Italians or Spaniards, and another by the Federation of German Wholesale and Foreign Trade (BGA), which feared the collapse of the Eurozone. By 30 March, volumes of tweets in French and German had returned to pre-Cyprus levels. A high proportion of the remaining French conversations still discussed Cyprus (92 per cent on 30 March) – while tweets in German had become more wide-ranging.
DiscussionThe issue of Cyprus caused a long-running twitcident, following the many twists and turns of the story as it evolved over a number of days. It showed the two important functions of Twitter that underlie many twitcidents: a way of sharing information to announce and learn about important events and keep apace with them as they rapidly develop, and a way of exchanging opinion about those events.
News of the Cyprus bailout had different implications for the Germans and the French. While it caused similar immediate surges of conversations on Twitter in both languages, in France, the conversation remained tightly focused on Cyprus, and conversations declined as the prominence of the issue of Cyprus itself declined. In Germany, it awakened a broader conversation about the Eurozone, its future, and Germany’s place within it, which continued on Twitter beyond the issue of Cyprus itself.
The overall attitudes expressed throughout the twitcident were critical towards the Cyprus bailout (often in solidarity with Cypriot depositors), sceptical that it would stabilise Cyprus, and in broader terms increasingly concerned about the stability of the Eurozone, and the implications of the instability for the individual and their own national economy. This is consistent with what else we know about attitudes on this subject. A Guardian poll in March 2013 found 91 per cent of people thought ‘this is just the beginning of the island’s problems’, and only 9 per cent that ‘the agreement means things can only get better’. [56] This concern for the economic future of neighbours, at the same time as concern for what it means for themselves, has divided the French and German electorates – slightly more than half of Germans generally support helping others, while 60 per cent of French people are against it. [57] On the specific issue of Cyprus, Germans supported the bailout, and French people opposed it. [58]
Case study 2: European institution events
European Commission Summit: 13–16 March 2013On 14 March 2013, the leaders of EU member states met in Brussels. From 13 to 16 March, there was a clear spike in the volume of tweets in English about José Manuel Barroso, reaching around ten times the background average on the day of the summit. [59] The increase in traffic lasted for three days, with smaller spikes in volume on the afternoons of 13 March and 15 March surrounding the most significant spike on the afternoon of 14 March (figure 3).
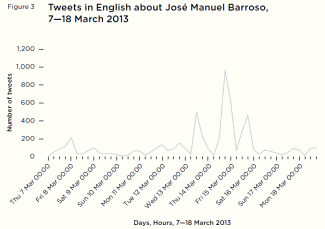 Figure 3 Tweets in English about José Manuel Barroso, 7—18 March 2013
Figure 3 Tweets in English about José Manuel Barroso, 7—18 March 2013Of the 3,518 English language tweets ‘relevant’ to José Manuel Barroso from the beginning of 13 March to the end of 15 March, over 70 per cent of tweets were about the summit. Yet an unusually low number (1,394, or around 40 per cent) shared a link, and no single story was notably dominant. The top ten most shared stories constituted only 299 (21 per cent) linkshares (seven of these ten were official EU websites, primarily covering a speech by Barroso in anticipation of the summit). There was a wide variety of coverage about the summit the day before (13 March), including a number of press releases and speeches by European politicians, and during the summit itself (on 14 and 15 March).
Instead of a single issue dominating discussion, users took the occasion of the summit to talk about the issues related to the EU that affected them. The summit therefore acted as a sounding board for a range of different concerns, fears and hopes that people felt about the EU.
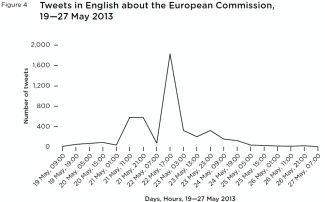 Figure 4 Tweets in English about the European Commission, 19—27 May 2013
Figure 4 Tweets in English about the European Commission, 19—27 May 2013This analysis found that 45 per cent of tweets were about the EU generally, which includes tweets concerning the EU budget, the European Commission, the European Parliament, the EU’s relationship with Russia and a series of other issues related to single member states. One in three of the tweets voiced economic concerns, discussed healthcare policies or demanded new initiatives in the social sphere.
European Commission Opening: 22 MayAfter a series of anticipatory press releases and briefings on 21 May, The European Commission opened on 22 May 2013. Also beginning on 21 May and continuing until 22 May, there was a sharp spike in the number of tweets in English ‘relevant’ to José Manuel Barroso (figure 4).
The first surge of tweets (between 8am and 5pm on 21 May) was primarily reportage of the upcoming Commission launch, sharing links to the publications released in anticipation of it. The overwhelming majority of tweets from 21 May referred to the publication of the European Commission’s (and José Manuel Barroso’s) contribution to the European Council meeting the following day, which called for measures on tax evasion (including full tax data exchange) and, to a lesser extent, progress on energy policy.
The second surge, predictably, was a body of reaction to the opening of the European Commission itself. As above, no single issue was dominant – the opening of the Commission spurred people to talk about their own, specific concerns and interests in relation to the EU. The topics raised were diverse, from tax evasion proposals to youth unemployment, the debate about arming Syrian rebels, and David Cameron’s remarks about lower taxes for business to increase growth and employment. A significant minority were ‘live tweets’ – people commenting directly about statements as they were made.
We therefore trained a classifier to distinguish between tweets that were in general optimistic, pessimistic or neither (irrelevant) about the European Commission’s ability to enact positive influence on their lives. [60] Of 1,684 tweets that were posted during the duration of the summit itself, 667 were broadly optimistic, and a very large majority of the rest were non-attitudinal or irrelevant. The generally optimistic attitude of Twitter users towards the Commission’s opening is surprising – and appears in direct contradiction to other data about attitudes.
DiscussionPeople understood and related to these European Commission events through the lens of their own specific grievances, concerns and priorities. They therefore provoked a different kind of twitcident – a heterogeneous collection of different volunteered statements that suggest people’s underlying issues of interest and concern. The longer duration illustrates how Twitter can move beyond knee-jerk reaction to a sustained engagement with current affairs as they play out across our computer screens.
Case study 3: European Court of Human Rights controversies
Example 1: ‘Casse toi pov’con’In 2008 Hervé Eon was arrested for waving a small placard exclaiming ‘Casse toi pov’con’ (‘Get lost you sad prick!’) during a visit of then French President Nicolas Sarkozy to the French town of Laval and convicted under an old French law that forbids insulting the head of state. His initial conviction was appealed at the ECHR, on the basis that his freedom of expression had been infringed. On 14 March, it was reported that the ECHR had ruled in his favour, arguing that by repeating a phrase (‘Eh ben casse toi alors, pauv’ con!’), which Sarkozy himself had used during a visit to the Salon de l’Agriculture in 2008 (and which subsequently went viral) the individual was using political satire, which should be protected as legitimate political criticism under human rights law.
A sudden surge of tweets in French ‘relevant’ to the ECHR began at 9am on 14 March, which lasted for around 24 hours. This was a sharp and symmetrical twitcident, beginning at 6am, peaking around midday at just over 1,800 tweets, and declining over the afternoon and the evening of that day (figure 5).
Within that total surge of 2,710 tweets, 1,934 of the tweets (71 per cent) directly referred to the case by the ‘casse toi’ quote in the tweet text itself, and 865 used a relevant #hag. Threequarters (2,025) shared a link, most prominently (451 shares in total) to the article in Le Monde61 that originally broke the news, while similar articles in other mainstream new outlets (Le Figaro, Le Nouvel Observateur, Libération, Le Parisien, 20 Minutes, France Info) were also widely shared. However, the second most widely shared link (240 shares) was to the actual ruling itself made by the court. [62]
Around two-thirds of these tweets did not express an attitude, but simply shared the story or the court’s decision without further elaboration. The vast majority of the remaining attitudinal tweets were positive about the ruling. Most took a light-hearted tone: ‘Let’s not hide our pleasure: let’s tweet it!’ Many praised or thanked the ECHR explicitly. One tweet reported the court’s decision then added, ‘That’s what Europe is for.’
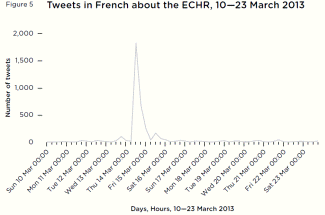 Figure 5 Tweets in French about the ECHR, 10—23 March 2013 Case studies of real world eventsExample 2: The deportation of Abu Qatada
Figure 5 Tweets in French about the ECHR, 10—23 March 2013 Case studies of real world eventsExample 2: The deportation of Abu QatadaAbu Qatada al-Filistini, a Palestinian Muslim of Jordanian citizenship, had since 2002 been the subject of a long legal battle to deport him from the UK to Jordan, where he had been sentenced to life imprisonment for conspiracy to carry out terror attacks. In 2012 the ECHR – the last legal hurdle to deportation – had ruled that sending Qatada to Jordan would violate his right to a fair trial.
According to one poll, 61 per cent of Britons supported the view that Britain should ‘ignore the court ruling’ and ‘deport Abu Qatada anyway’. [63] Most people pointed to the ECHR, ahead of the home secretary or civil servants, as the reason for the delay. [64] On the morning of 24 April 2013, it was reported that David Cameron was exploring ‘every option’, widely understood to mean a temporary withdrawal from the European Convention of Human Rights, in order to deport Abu Qatada to Jordan. This temporary withdrawal followed by a reratification with certain reservations, it was announced, had been discussed between David Cameron and other cabinet-level ministers.
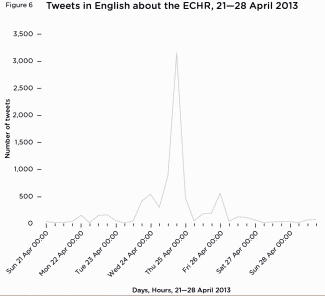 Figure 6 Tweets in English about the ECHR, 21—28 April 2013
Figure 6 Tweets in English about the ECHR, 21—28 April 2013Spurred on by this announcement, a passionate debate took place on Twitter about the relative merits of leaving the ECHR in order to deport Abu Qatada. On 23–24 April 2013 the number of English language tweets discussing the ECHR increased above the background level, and surged to a peak of over 3,000 around 5pm (figure 6).
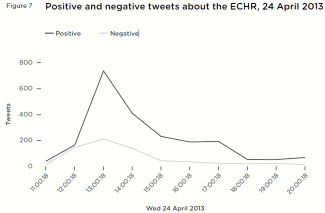 Figure 7 Positive and negative tweets about the ECHR, 24 April 2013
Figure 7 Positive and negative tweets about the ECHR, 24 April 2013 Over the days of 24 and 25 April 2013, 5,834 tweets in English ‘relevant’ to the ECHR were posted. Cameron’s proposal dominated this discussion – 94 per cent of the tweets randomly selected were related to it and 1,785 of these shared a link. The most shared stories were mainstream media and blogs discussing the Government’s proposals. This wider body of shared commentary was primarily hostile to the proposal to leave the ECHR, including a widely circulated and (critical) legal opinion from the campaign group Liberty about the lawfulness of the UK Government’s proposal, and a recording of Thomas More’s speech on the primacy of man’s laws over God’s laws (also deployed in apparent criticism of Cameron’s proposal), which appeared on YouTube.
The majority of tweets were also strongly hostile to the idea of a temporary withdrawal from the ECHR: ‘The rule of Law clearly means nothing to this government. It is absolutely shocking #ECHR.’ Some fitted the suggested move into a wider narrative of recent illiberal government policies; some argued it was a slippery slope towards further abuses; some pointed out the absurdity of such a large change for one person; and many questioned whether it was legally possible: ‘Actually quite worried about only having rights when it’s convenient to my government. This is not how it’s supposed to work. #echr.’ However, a smaller group argued that Abu Qatada should be deported at all costs, and Britain did not need the European Convention on Human Rights to safeguard its liberties.
A classifier was trained to classify each tweet as ‘positive’ towards the ECHR (and therefore hostile to Cameron’s proposal to withdraw from it), ‘negative’ towards the ECHR, or ‘non-attitudinal/irrelevant’. Of 1,344 attitudinal tweets, 1,181 (88 per cent) were classified as positive, and 163 negative (12 per cent) (figure 7).
DiscussionThe case of the French response to the story of Hervé Eon shows how Twitter is used not only to express disagreement and discontent at perceived injustices but also to thumb one’s nose at authority – as demonstrated by the repeated use of the very phrase that had landed Eon in trouble. Regarding Abu Qatada, we again see a strong reaction against perceived authoritarianism. Both incidences are examples where some domestic authority – a French court, the British prime minister – is seen to take or propose a drastic measure at odds with European legal institutions, and in both instances Twitter users sided with Europe (although this may also be a response to domestic political issues).
The very strong signal of hostility towards Cameron’s proposal and support for the court is consistent with evidence from opinion polls on British views towards the legitimacy of the ECHR. While, unlike many other European countries, the court was viewed in the UK as something that both improved and harmed democracy, twice as many people viewed its influence to be broadly positive as those who considered it negative.Case study 4: José Manuel Barroso on the French economyAt 6.30 (GMT) on 15 May 2013, the French National Institute of Statistics and Economic Studies (INSEE) announced that the French economy was officially in recession (−0.2 per cent growth for the second consecutive quarter) while François Hollande was due to meet all 27 European Commissioners later in the day to request an extension for France’s budget reforms.
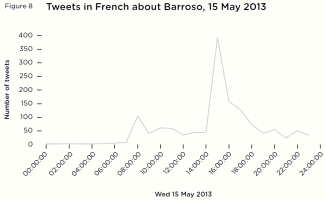 Figure 8 Tweets in French about Barroso, 15 May 2013
Figure 8 Tweets in French about Barroso, 15 May 2013Barroso was interviewed at 7.20am about his reaction to the French recession and the upcoming meeting with Hollande. Meanwhile, the number of French language tweets about Barroso began to surge. Volumes increased even more sharply that afternoon as in a joint French language press conference at 2pm Hollande and Barroso announced the outcome of that meeting – a grudging acceptance of a two-year extension.
From a background average of 86 per day, 1,419 French language tweets about Barroso arrived over 24 hours on 15 May 2013 – peaking during Hollande and Barroso’s joint press conference (figure 8). [65]
Around 40 per cent of these tweets shared a link, and many of these shared a version of a media narrative that dominated the depiction of the relationship between Barroso and Hollande – that Barroso was admonishing Hollande for failure (table 4).
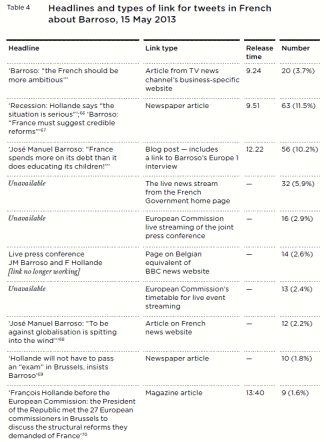 Table 4 Headlines and types of link for tweets in French about Barroso, 15 May 2013
Table 4 Headlines and types of link for tweets in French about Barroso, 15 May 2013Barroso’s statements were remarkably incendiary – that France lacked ambition and France prioritises debt servicing over educating its children. Given this dynamic, a classifier was created to identify whether the tweets within the twitcident were supportive of Barroso’s statements, unsupportive, or neither. [71] The ‘neither’ category included any non-attitudinal linkshares, and straight quotations or paraphrases, as well as tweets that were not about Barroso (eg attitudes about or quotes from Hollande).
Over the entire twitcident, the classifier found 19 supportive tweets (1.4 per cent), 363 unsupportive tweets (27.1 per cent) and 956 tweets that were neither (71.4 per cent). Over time, the classifier suggests there was a large number of neutral, ‘reporting’ tweets, followed by a smaller number of ‘commentary’ tweets that were, on the whole, unsupportive. These criticisms of Barroso ranged from the polite – #Barroso ‘Nous attendons des réformes crédibles de la France’ Celles de FH [François Hollande] ne le seraient elles pas jusqu’à maintenant?’ (‘We await credible reforms from France’) – to outright attacks – #BarrosoOnTeMerde.
Case study 5: a possible ban on pornographyIn the late evening of 6 March 2013 the news was circulated that the Women’s Rights and Gender Equality Committee of the European Parliament had proposed a vote to ban pornography from all forms of media, so that a ‘true culture of equality’ could be achieved in the digital world.
The next morning, the number of German conversations ‘relevant’ to the European Parliament surged from a very low background level to 318 tweets sent over the course of that day, 7 March 2013; 301 of these tweets shared a link and the two most shared – together comprising 196 of these linkshares – discussed the Committee’s recommendation.
There were two significant spikes in the volume of tweets in German ‘relevant’ to the European Parliament – one over 7 and 8 March, the second beginning of the morning of 12 March and continuing until 6pm on 13 March. Consistent between these two clusters of two days, the spike in volume was sharp and symmetrical; there was a rapid rise in the number of tweets from lunchtime to evening, and a rapid decline to very low levels from the evening to that night (figure 9).
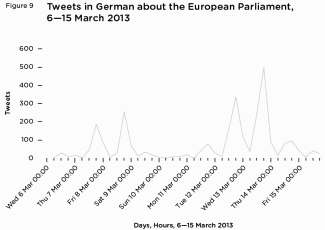 Figure 9 Tweets in German about the European Parliament, 6—15 March 2013
Figure 9 Tweets in German about the European Parliament, 6—15 March 2013On 7 March 2013, 89 per cent of tweets referred to the possibility of a ban on pornography, but 68.5 per cent did not record an attitudinal view. Of those that did, the majority (57 per cent) were relatively dismissive of the plan, seemingly viewing this proposal as unlikely to garner any substantial support with the European Parliament; the remainder were highly critical of the potential pornography ban. Indeed, these tweets revolved around the theme that the European Parliament simply did not, or should not, have the authority to enforce such a ban.
On 8 March, as the story reached a broader public, thousands of emails began to arrive from concerned voters to their members of the European Parliament (MEPs). However, at around 12 midnight, the flow of emails was suddenly interrupted. Christian Engström, MEP for the Swedish Pirate party, publicly announced that after receiving more than 350 protest emails, they had suddenly ceased. It was soon discovered (with around half of all tweets that day sharing a link to the story) that following complaints by a number of MEPs, the European Parliament’s IT Department had started to filter out these emails as spam.When the news broke that the European Parliament had enforced an email filter, the story was reflected on Twitter too: 83 per cent of tweets were about the EU Parliament blocking emails. Of these tweets, 76 per cent did not display a negative or positive attitude towards this measure. However, the 24 per cent of tweets that did convey an attitude were almost unanimous in tone – that this episode was a prime example of the European Parliament repressing the opinions of voters (EU citizens), and demonstrated how out of touch the EU institutions had become.
The vote on the proposal took place on 12 March 2013 and concluded at around 1pm. The European Parliament approved the overall report on gender inequalities with 368 out of 625 members voting in favour, but rejected the controversial section containing the ban on pornography. The four most shared stories that day reported on the vote. However, the following day, the largest daily spike in relevant tweets across all three months (early March to early June) (872) focused on a completely different story – the overwhelming rejection by the EU Parliament of the tabled 2014–2020 EU budget ‘in its current form’. The topics of the tweets over 12 March and 13 March therefore drastically changed in reaction to this important announcement.
DiscussionThe proposed ban on pornography shows how Twitter is used first to share information about events, especially from mainstream media, and then to talk about them.
The proposed ban allowed people to think about wider European legal institutions and what should be the limit of their power. Broadly, in this instance, Twitter users were supportive of the existing way of things. The blocking of emails critical of the proposed measure shows precisely how sensitive Twitter is to what its users perceive as injustices. However, it seems that to be popular, the message also has to be self-contained, and to demonstrate what it needs to, whether through a photo or link, within the bounds of Twitter itself.