Re: There’s No Comparing Male and Female Harassment Online
Executive summary
Trust, engagement and support for the European Union (EU) is on a downward path. It suffers from a democratic deficit: the perception and reality that there is a large distance in understanding and reality between the governors and the governed. Democratic representation must mean more than electoral success – it must also include ‘responsive listening’: listening to people, understanding their fears, priorities and aspirations, and reacting to what is heard and learnt. Listening is a vital link between people and institutions, which underlies the practical, everyday task of representing people, and discharging a mandate on their behalf.
There are now more opportunities to listen than ever before. Over the last decade European citizens have gained a digital voice. Close to 350 million people in Europe currently use social networking sites – three in four EU citizens. More of us sign into a social media platform at least once a day than voted in the last European elections. Facebook has 232 million users across the EU and 16 per cent of European internet users have a Twitter account. EU citizens have transferred many aspects of their lives onto these social media platforms, including politics and activism. They use social media to discuss news stories, join political movements, organize new political movements and broadly discuss and dissect those public issues that matter to them, across boundaries and at essentially no cost. Taken together, social media represent a new digital commons, central places of assembly and interchange where people join their social and political lives to those around them. It is a new, focal theatre for Europe’s daily political life.
We have never before had access to the millions of voices that together form society’s constant political debate, nor the possibility of understanding them. Capturing and understanding these citizen voices potentially offers a new way of listening to people, a transformative opportunity to understand what they think, and a crucial opportunity to close the democratic deficit.
However, making sense of digital voices requires a new kind of research. [1] Traditional attitudinal research relies on tried and trusted methods and techniques: the focus group, the interview, the national poll. But turning the cacophony of sometimes millions of social media conversations into meaning and insight requires the use of powerful new technologies that are capable of automatically collecting, storing, analysing and visualising information. This throws up questions of trust and rigour at every stage of the research cycle: the role of technology and automation, how to sample the data, how to make sense from the noise, how to interpret the information appropriately and use it, and how to do this all ethically.
This paper examines the potential of listening to digital voices on Twitter, and how far it might be an opportunity to close the democratic deficit. It looks at how European citizens use Twitter to discuss issues related to the EU and how their digital attitudes and views about the EU are evolving in response to political and economic crises faced by the EU. We ask whether social media analysis can provide a new way for the EU’s leaders to apprehend, respond and thereby represent its citizens. It addresses the many formidable challenges that this new method faces: how far it can be trusted, when it can be used, the value such use could bring, and how its use can be publicly acceptable and ethical.
Listening to digital voices
The potential of social media as a source of attitudinal insight was tested using the practical case of the EU. The period between March and June 2013 was an extremely difficult time for the EU and related institutions. There were a series of economic bailouts, landmark and controversial European Court of Human Rights rulings, and the opening of the European Commission.
We investigated two key themes:
• What kind of digital voices exist? How do EU citizens use Twitter to discuss issues related to the EU? What kind of data does Twitter therefore produce?
• How do we listen to these voices? To what extent can we produce meaningful insight about EU citizens’ attitudes by listening to Twitter? How does this relate to other kinds of attitudes, and other ways of researching them?
Over this period around 3.26 million publicly available tweets were collected directly and automatically from Twitter in English, French and German, which contained a keyword considered relevant to one of six themes selected. These represent the many identities the EU has for the people who talk about it: an institution that drafts laws and enacts and enforces them, a collection of institutions which define and shape their economic lives, and a body of politicians and civil servants.
The volume of data collected was too large to be manually analysed or understood in its totality. We therefore trialled a number of different methods – automated and manual, some highly technological and others straightforward – to understand it. These included:
• data overview: examining the general characteristics of the Twitter data for each data stream such as volume of hash tags, retweets, linkshares, user mentions and traffic analysis
• testing natural language processing: which allows researchers to build algorithms that detect patterns in language use that can be used to undertake automatic meaning-based analysis of large data sets; these were built and applied in different contexts to see where it worked, and where it did not; these algorithms are called ‘classifiers’ – the research team built over 70 such classifiers, and tested how well they performed against human analyst decisions
• manual and qualitative analysis: using techniques from content analysis and quantitative sociology to allow analysts to manually discern meaning from tweets
• five case studies: examining how Twitter users responded to events as they happened in the real world, and whether they could be reliably researched
It was unclear at the outset what combination, and in what context, of these kinds of analysis would be effective or reliable. Different frameworks of use were therefore flexibly and iteratively applied throughout the course of the project.
Europe’s new digital voice
This is a summary of what we found:
There are millions of digital voices talking about EU-related themes in real time; it is a new venue for politics
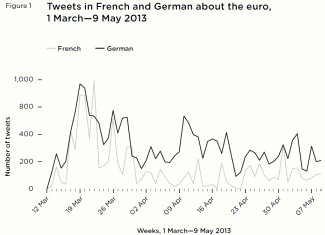
In four months, we collected 1.91 million tweets in English across the six English data streams; 1.04 million across the six French data streams; and 328,800 across the six German data streams. We considered 1.45 million tweets across all three languages to be ‘relevant’ to one of the six EU-related themes. This included almost 400,000 tweets about the euro currency in English, and 430,000 about the EU. [2]
These voices are event-driven and reactive, not steady and general
Most of the data collected are of people reacting to events, such as a major speech, ruling, or news story. These offline events provoke groundswells of online reaction that shadow events that have occurred offline – each a collectively authored digital annotation of the event, containing questions, interpretations, condemnations, jokes, rumours and insults. These ‘twitcidents’ will become a routine aftermath, a usual way that society reacts to and annotates the events it experiences.
These voices share information about events and express attitudes about them
Tweets were often used to keep up with recent developments in a rapidly changing world. Over half of every data set was tweets that shared a link to a site beyond Twitter, primarily to media stories, often containing no additional comment by the tweeter themselves. Where attitudes were expressed, it was often in the form of non-neutral reportage of a specific event.
Making sense of the noise: digital observation
These voices cannot be listened to in conventional ways. Twitter data sets are ‘social big data’. Conventional methods to gather and understand attitudes – polls, surveys and interviews – are overwhelmed by how much or how quickly data are created. Twitter offers a novel way of understanding citizens’ attitudes and reactions to events as they unfold, in a way that can be extremely powerful and useful for academics, researchers, advocacy groups, policy makers and others. Twitter is a new type of reactive, short-form expression, produced in large volume, and above all driven by events.
Current ways of researching society cannot handle these kinds of data in the volumes that are now produced. While there is a burgeoning industry in applying new computational techniques to try to analyse social media data, it can be misleading, and often hides sociologically invalid modes of collection and analysis. This is most important for the most popular way of analysing social media content ‘sentiment analysis’, which breaks conversations into ‘positive’, ‘negative’ and ‘neutral’ categories. This kind of analysis often uses natural language processing (NLP) in ways that our pilot found unlikely to be successful – generic, standardised, operating over a long period of time, and not related or trained to a particular event or conversation.
We found that it is possible to create new ways of combining new technology and traditional methodologies to understand the groundswells of digital voices that rise in reaction to important events as they occur. Through trial and error and case studies, we developed an approach to analysing these data sets, which we call ‘digital observation’. This includes:
• collecting tweets directly from Twitter on a given theme as they are posted in real time
• identifying groundswells of tweeted reaction when they occur on a particular theme and identifying the event(s) that are driving it. Our case studies and classifier tests revealed that people do not in general express generic sentiment on Twitter Executive summary about the EU, instead, Twitter was found to be fundamentally a reactive medium; a tweet is overwhelmingly a reaction to an event that the tweeter has otherwise encountered – either online or offline, whether through reading mainstream media or being told by a friend. Therefore, it is best used as a way of gaining insight into how people respond to events, rather than as a continuous ‘poll’ of opinion. The closest analogy to the value of insight from Twitter is perhaps not the population level opinion poll, but rather the noise of a throng of energised citizenry talking about a particular event
• using automatic NLP to build algorithmic classifiers, which can filter out tweets that are irrelevant to the theme in question
• flexibly and reactively building bespoke technology around these specific events to listen to the digital voices – what they are saying and the attitudes, hopes, fears and priorities that they carry with them at scale and speed
• situating these attitudes within the background of the events that were occurring, the media reportage that covered them, and the public discussions that were being carried out
What are digital voices saying?
Using this method, we found a number of specific features about tweets relating to the EU:
The silent majority ‘reaction’ phenomenon
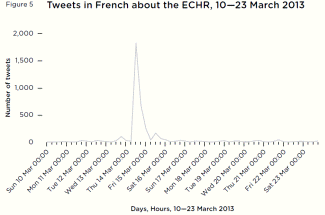
While the general consensus in the UK is that the population is broadly hostile to the European Court of Human Rights (ECHR), it is of note that the response following the Cameron suggestion about leaving the ECHR led to a groundswell of hostile criticism. Even when it came to a very unpopular ruling – preventing the UK from deporting Abu Qatada – most Twitter users rallied around the principle of the ECHR (of 1,344 attitudinal tweets about this decision, 1,181 were classified as pro-ECHR and 163 negative).
Commission events are a good opportunity to gauge general views
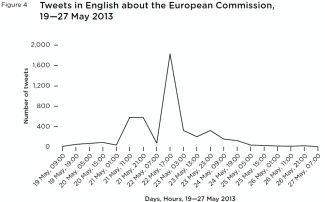
There is clearly a significant surge in activity surrounding major European events, such as summits – they are news stories in themselves. Rather than being based on a single news story (such as the other data sets) there was a significant number of tweets about the summit, which was an occasion for people to bring their own, related topics of concern to the table.
Variation across countries
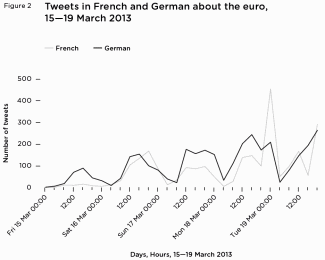
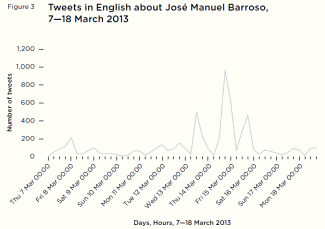
By listening to how people on Twitter reacted to certain events rather than as a continuous whole, they tell a story of users responding to each EU-related case separately and on broad national distinctions. French tweeters thought the European Central Bank was ‘strangling’ Cyprus, while German tweeters continued to worry about Germany’s place in the Eurozone. Both British and French tweeters broadly applauded the ECHR over their own national governments, but French tweeters did not like Barroso’s incendiary admonishments of Hollande and France.
Discussion: Twitter as a source of attitudinal data
Digital observation has considerable strengths and weaknesses compared with conventional approaches of studying attitudes. It is able to leverage more data about people than ever before, with hardly any delay and at very little cost. On the other hand, it uses new, unfamiliar technologies to measure new digital worlds, all of which are not well understood, producing event-specific, ungeneralisable insights that are very different from what has up to this point been produced by attitudinal research in the social sciences. Based on our research, we consider the following strengths and weaknesses to be most significant.
Strengths
Very large data sets available
Twitter data sets are ‘social big data’. The size of the data set gathered even for this pilot is far larger than comparative data sets gathered through conventional polling, interviewing and surveying techniques. Digital observation radically widens the number of voices that can routinely be listened to.
Real-time insight
Relevant tweets are collected almost immediately after they are posted. Digital observation, using automated technologies, draws meaning from these data very quickly after collection. It is therefore possible to understand attitudes about an event as the event happens, and as the public debate evolves. This is perhaps the most important distinction between digital observation and other ways of researching attitudes. Discerning real-time attitudes is a valuable power for institutions to have. It allows them to be agile, and react quickly to groundswells of anger, support or criticism quickly enough to influence the underlying developments and events that drive these attitudes.
‘In conversation’: listening rather than asking removes observation bias
A well-known weakness in most attitudinal research is that data are collected in ‘non-real world’ settings. Most ways of gathering attitudes require a researcher intervening in someone’s life – asking them questions, and recording what they say. This introduces ‘observation effects’, which change the attitudes expressed and views offered in a number of ways. [3] Digital observation avoids these unwanted distortions by listening to digital voices as they rise, naturally, on social media platforms.
Cheap
Attitudinal research is often expensive. It is expensive to employ interviewers and to manage and incentivise panels of participants, to mail surveys to thousands of people and to hire rooms, technology and people to conduct focus groups. Digital observation is very economic in comparison. Acquiring tweets (in certain contexts and quantities) is free and the technology, once in place, can be trained and purposed in a matter of minutes. This lowers the threshold for attitudinal research – many more organisations will be able to listen more often to more conversation that they care about.
Weaknesses
There is no accepted ‘good practice’ for digital observation
Established ways of researching attitudes have long histories of use. This experience has consolidated into a body of good practice – dos and don’ts – which, when followed, ensures the quality of the research. Digital observation does not have a long history of use, or an established collective memory of what works and what does not. It uses new technologies in new ways that are unfamiliar with the social sciences, often with new and important implications for research.
The performance of the technology varies considerably
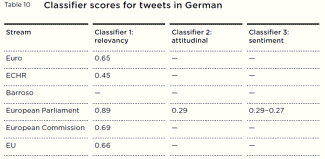
The technology sometimes performed very successfully, and at other times very poorly. In the research, the best performing classifiers were almost always correct, and the worst performing classifiers performed no better than chance. The performance of classifiers depends on the context of the task. We found that generic, long-term classifiers performed inaccurately. Language use – the kinds of words used and the meanings these words have – changes quickly on Twitter. Language is specific to a particular conversation at a particular time. Automated algorithms struggled to find generic meaning accurately independent of a particular event or discussion, and became drastically less accurate over a long period of time. However, bespoke short-term classifiers did well and proved to be able to reliably discern meaning, when trained on a specific event, at a specific time, and in a way that reflects the data. Classifiers performed best when making distinctions that reflected the data at a particular point. There are also other difficulties for classifiers. Non-literal language use, such as sarcasm, pastiche, slang and spoofs, are found to be common on social media. The ‘real’ rather than ironic meaning of these kinds of uses of language are inherently contextual and difficult to deduce via shallow automated analyses.
Sampling: the tweets that are gathered may systemically differ from those that are not
Data are acquired through Twitter by being matched to keywords. The pilots showed that these keywords can produce different kinds of problems – sometimes they are over-inclusive (and collect tweets on other, irrelevant topics), and sometimes they are under-inclusive (and miss relevant tweets). In both these ways, keyword matching is inherently prone to systemic bias – so data collected, and therefore the conclusions drawn, are affected in a non-random way by the search terms employed.
Insights from digital observation can be difficult to generalise
The power of much attitudinal research is that it creates representative data sets that allow for generalisations beyond the group that was actually asked – to age group, area, the country or even the world. Making these generalisations when using Twitter as a source of attitudinal data is difficult because of a problem of representativeness. Twitter users do not demographically represent wider populations: data are collected based on conversations rather than demographic details of a participant. Moreover, collected tweets often do not represent Twitter users. Tweets, in general, are produced by a small number of high-volume ‘power-users’. Compounding this problem, ‘power-users’ are sometimes automated, ‘bot’, fake, official or campaign accounts. Moreover, Twitter is a new social space, allowing the growth of a number of digital cultures and sub-cultures with distinct norms, ways of transacting and speaking and also a new communications medium whose format powerfully influences what is said and meant. The pace with which this context evolves and changes makes the meaning of tweets often unclear or ambiguous.
Recommendations and ways forward
Twitter has become an extremely significant venue for public debate and discussion. Increasingly, it is an important way for citizens to express their attitudes on a range of subjects, including the European project. We recommend that representative organisations examine ways to listen and respond to these digital voices:
Investigate digital observatories
Organisations, especially representative institutions, now have the opportunity to listen cheaply to attitudes expressed on Twitter that matter to them. They should consider establishing digital observatories that are able to identify, collect and listen to digital voices, and establish ways for them be reflected appropriately in how the organisation behaves, the decisions it makes and the priorities it has. Digital observatories, constantly producing real-time information on how people are receiving and talking about events that are happening, could be transformative in demonstrating how organisations relate to wider societies. Just because it is possible to collect social media data does not mean it should be done. Digital observatories should be predicated on public understanding and openness about how they work; and conducted according to strict ethical principles for the collection analysis and use of data. This type of research should not replace existing methods of research, but supplement it.
The EU must adopt a leadership role on how to listen to citizens ethically and robustly
Increasingly, politics is moving online, enabling people to express opinions, politicians to mobilise voters, and anyone to form parties and movements. This opens new roles and opportunities for research to be powerful and useful: to rework communication campaigns that are misunderstood; to delay or halt policy roll-outs that have unintended and unforeseen consequences; and more broadly to allow those in democratic institutions to perceive, react to and represent views during the time when they most matter – as they are expressed. However, as a new field, this also creates ethical risks and dangers of poor research methods. To be a leader in the democratic governance and representation of an increasingly digital world, the EU must stake out leadership in the ethical and effective exploitation of these new technologies, grasping the opportunities they now offer.
Nine principles for social media research
Our ability to understand Twitter as a source of attitudes is nascent. Many of the tools that can handle large numbers of tweets have come from the computer science departments of academia, and the public relations and advertising industries. Their up-take within the sociological, psychological and anthropological disciplines has been slower, and new technologies have often not been reconciled with the values and principles of conventional attitudinal research.
It is necessary to arrive at a new discipline capable of turning social media into social meaning. This pilot demonstrated the strength of combining human and technological analysis, built around a specific event as it happens.
For this to be realised, we recommend the following nine principles for undertaking high quality social media research. They are designed for researchers, advocacy groups and others interested in understanding society, as a set of techniques approaches and methods for how to make the best use of these techniques, and turn the potential of listening to the digital voices into something useful and valuable:
1 Beware the numbers game and ‘sentiment analysis software’ – this will not always deliver the best results and can be misleading
Size is not everything. While there is a burgeoning industry in analysing social media, very large amounts of data often hide sociologically invalid modes of collection and analysis. This is most important for the most popular way of analysing social media content ‘sentiment analysis’, which breaks conversations into ‘positive’, ‘negative’ and ‘neutral’ categories. This kind of analysis often uses NLP in ways that our pilot found unlikely to be successful – generic, standardised, operating over a long period of time and not related to a particular event or conversation.
2 Digital observation can complement existing polling data, but not replace them
It is therefore necessary to use a new approach to ‘attitudes’ that reacts to events in real time. Traditional, representative polling data still remain an extremely powerful way to ascertain attitudinal data, especially across large populations. It is based on tried and tested methods of randomised sampling and questionnaire design. Twitter data are of a different nature – dynamic, unstructured and event-driven. They should be viewed as a complement to, rather than replacement for, traditional polling.
3 Look for ways to mix qualitative and quantitative, automated and manual methods
Automated techniques are only able to classify social media data into one of a small number of categories at a certain (limited) level of accuracy for each message. They are a good first way to tackle scales of data that would otherwise be overwhelming. Manual analysis is therefore almost always a useful and important component; in this report it is used to look more closely at a small number of randomly selected pieces of data drawn from a number of these categories. In scenarios when a deeper and subtler view of the social media data is required, the random selection of social media information can be drawn from a data pool, and sorted manually by an analyst into different categories of meaning.
4 Involve human analyst and subject matter expertise at every step
It is vital that attempts to collect and analyse attitudinal ‘big data’ is guided by an understanding of what is to be studied: how people express themselves, the languages that are used, the contexts – social and political – that attitudes are expressed in, and the issues that they are expressed about. Analysts who understand the issues and controversies that surround the EU are therefore vital in order to contextualise and explain the attitudes that are found on Twitter, and to help build the methods that are used to find and collect these attitudes.
5 Beyond the ‘black box’ – new big data technologies must be presented in a way that non-specialists can understand
Non-technical specialists are often the end-users of the research, and it is vital that the technology, however sophisticated, is explained in a way that clearly lays out how it was used and what the implications of its use are. This means clarity and detail must be provided about how the search terms were constructed and why, what type of data access terms were used, how well the classifier performed against a human analyst, and what the likely biases in the data were.
6 Use new technologies in contexts where they work. NLP classifiers should be bespoke, not generic and driven by the data rather than predetermined
Overall, NLP classifiers seem to perform best when they are bespoke and event-driven rather than generic. When categories to sort and organise data are applied a priori, there is a danger that they reflect the preconceptions of the analyst rather than the evidence. It is important that classifiers should be constructed to organise data along lines that reflect the data rather than the researcher’s expectations. This is consistent with a well-known sociological method called grounded theory. [4]
7 New roving, changeable sampling techniques
The collection of systemically biased data from Twitter is far from easy. The search terms that are used are vulnerable to Twitter’s viral, short-term surging variations in the way that language is used to describe any particular topic, so keyword searches are liable to result in bias and/or incomplete data sets. Therefore, development is needed to improve ways of sampling in a more coherent and repeatable way.
8 From metrics to meaning
Numbers and measurements alone cannot talk for themselves, and do not represent meaningful insight that can be acted on. It is here, in the ability to translate measurements into insight and understanding that can be acted on, that most work is required. Findings from digital observation must be intensively contextualised within broader bodies of work in order to draw out causalities and more general insights.
9 Apply a strict ethical approach at every step
Researching people entails moral hazard. Research can harm the individual participants involved or more broadly the society from which they are drawn. Ethical codes of conduct are used by researchers to minimise these harms, and balance them against the social benefits of the research. In the UK, the standard best practice for research ethics is the ethical framework of the Economic and Social Research Council (ESRC), which is made up of six principles. [5] It is unclear, however, how these can be applied for the mass collection of social media data. At the time of this writing, no official frameworks on internet research ethics have been adopted at any national or international level.[6] Social media research of this kind is a new field, and the extent to which (and how) these ethical guidelines apply practically to research taking place on social media is unclear. We consider that the two most important principles to consider for this type of work are whether informed consent is necessary to reuse the Twitter data that we collected, and whether there are any possible harms to participants in republishing their tweets that must be measured, managed and minimised. Researchers must bear these considerations in mind at all times, and not assume that because data are available it is necessarily ethical to access and use them. We therefore suggest that all academic research work that involves collecting social media data relating to individuals should be subject to ethical review boards.
Trust, engagement and support for the European Union (EU) is on a downward path. It suffers from a democratic deficit: the perception and reality that there is a large distance in understanding and reality between the governors and the governed. Democratic representation must mean more than electoral success – it must also include ‘responsive listening’: listening to people, understanding their fears, priorities and aspirations, and reacting to what is heard and learnt. Listening is a vital link between people and institutions, which underlies the practical, everyday task of representing people, and discharging a mandate on their behalf.
There are now more opportunities to listen than ever before. Over the last decade European citizens have gained a digital voice. Close to 350 million people in Europe currently use social networking sites – three in four EU citizens. More of us sign into a social media platform at least once a day than voted in the last European elections. Facebook has 232 million users across the EU and 16 per cent of European internet users have a Twitter account. EU citizens have transferred many aspects of their lives onto these social media platforms, including politics and activism. They use social media to discuss news stories, join political movements, organize new political movements and broadly discuss and dissect those public issues that matter to them, across boundaries and at essentially no cost. Taken together, social media represent a new digital commons, central places of assembly and interchange where people join their social and political lives to those around them. It is a new, focal theatre for Europe’s daily political life.
We have never before had access to the millions of voices that together form society’s constant political debate, nor the possibility of understanding them. Capturing and understanding these citizen voices potentially offers a new way of listening to people, a transformative opportunity to understand what they think, and a crucial opportunity to close the democratic deficit.
However, making sense of digital voices requires a new kind of research. [1] Traditional attitudinal research relies on tried and trusted methods and techniques: the focus group, the interview, the national poll. But turning the cacophony of sometimes millions of social media conversations into meaning and insight requires the use of powerful new technologies that are capable of automatically collecting, storing, analysing and visualising information. This throws up questions of trust and rigour at every stage of the research cycle: the role of technology and automation, how to sample the data, how to make sense from the noise, how to interpret the information appropriately and use it, and how to do this all ethically.
This paper examines the potential of listening to digital voices on Twitter, and how far it might be an opportunity to close the democratic deficit. It looks at how European citizens use Twitter to discuss issues related to the EU and how their digital attitudes and views about the EU are evolving in response to political and economic crises faced by the EU. We ask whether social media analysis can provide a new way for the EU’s leaders to apprehend, respond and thereby represent its citizens. It addresses the many formidable challenges that this new method faces: how far it can be trusted, when it can be used, the value such use could bring, and how its use can be publicly acceptable and ethical.
Listening to digital voices
The potential of social media as a source of attitudinal insight was tested using the practical case of the EU. The period between March and June 2013 was an extremely difficult time for the EU and related institutions. There were a series of economic bailouts, landmark and controversial European Court of Human Rights rulings, and the opening of the European Commission.
We investigated two key themes:
• What kind of digital voices exist? How do EU citizens use Twitter to discuss issues related to the EU? What kind of data does Twitter therefore produce?
• How do we listen to these voices? To what extent can we produce meaningful insight about EU citizens’ attitudes by listening to Twitter? How does this relate to other kinds of attitudes, and other ways of researching them?
Over this period around 3.26 million publicly available tweets were collected directly and automatically from Twitter in English, French and German, which contained a keyword considered relevant to one of six themes selected. These represent the many identities the EU has for the people who talk about it: an institution that drafts laws and enacts and enforces them, a collection of institutions which define and shape their economic lives, and a body of politicians and civil servants.
The volume of data collected was too large to be manually analysed or understood in its totality. We therefore trialled a number of different methods – automated and manual, some highly technological and others straightforward – to understand it. These included:
• data overview: examining the general characteristics of the Twitter data for each data stream such as volume of hash tags, retweets, linkshares, user mentions and traffic analysis
• testing natural language processing: which allows researchers to build algorithms that detect patterns in language use that can be used to undertake automatic meaning-based analysis of large data sets; these were built and applied in different contexts to see where it worked, and where it did not; these algorithms are called ‘classifiers’ – the research team built over 70 such classifiers, and tested how well they performed against human analyst decisions
• manual and qualitative analysis: using techniques from content analysis and quantitative sociology to allow analysts to manually discern meaning from tweets
• five case studies: examining how Twitter users responded to events as they happened in the real world, and whether they could be reliably researched
It was unclear at the outset what combination, and in what context, of these kinds of analysis would be effective or reliable. Different frameworks of use were therefore flexibly and iteratively applied throughout the course of the project.
Europe’s new digital voice
This is a summary of what we found:
There are millions of digital voices talking about EU-related themes in real time; it is a new venue for politics
In four months, we collected 1.91 million tweets in English across the six English data streams; 1.04 million across the six French data streams; and 328,800 across the six German data streams. We considered 1.45 million tweets across all three languages to be ‘relevant’ to one of the six EU-related themes. This included almost 400,000 tweets about the euro currency in English, and 430,000 about the EU. [2]
These voices are event-driven and reactive, not steady and general
Most of the data collected are of people reacting to events, such as a major speech, ruling, or news story. These offline events provoke groundswells of online reaction that shadow events that have occurred offline – each a collectively authored digital annotation of the event, containing questions, interpretations, condemnations, jokes, rumours and insults. These ‘twitcidents’ will become a routine aftermath, a usual way that society reacts to and annotates the events it experiences.
These voices share information about events and express attitudes about them
Tweets were often used to keep up with recent developments in a rapidly changing world. Over half of every data set was tweets that shared a link to a site beyond Twitter, primarily to media stories, often containing no additional comment by the tweeter themselves. Where attitudes were expressed, it was often in the form of non-neutral reportage of a specific event.
Making sense of the noise: digital observation
These voices cannot be listened to in conventional ways. Twitter data sets are ‘social big data’. Conventional methods to gather and understand attitudes – polls, surveys and interviews – are overwhelmed by how much or how quickly data are created. Twitter offers a novel way of understanding citizens’ attitudes and reactions to events as they unfold, in a way that can be extremely powerful and useful for academics, researchers, advocacy groups, policy makers and others. Twitter is a new type of reactive, short-form expression, produced in large volume, and above all driven by events.
Current ways of researching society cannot handle these kinds of data in the volumes that are now produced. While there is a burgeoning industry in applying new computational techniques to try to analyse social media data, it can be misleading, and often hides sociologically invalid modes of collection and analysis. This is most important for the most popular way of analysing social media content ‘sentiment analysis’, which breaks conversations into ‘positive’, ‘negative’ and ‘neutral’ categories. This kind of analysis often uses natural language processing (NLP) in ways that our pilot found unlikely to be successful – generic, standardised, operating over a long period of time, and not related or trained to a particular event or conversation.
We found that it is possible to create new ways of combining new technology and traditional methodologies to understand the groundswells of digital voices that rise in reaction to important events as they occur. Through trial and error and case studies, we developed an approach to analysing these data sets, which we call ‘digital observation’. This includes:
• collecting tweets directly from Twitter on a given theme as they are posted in real time
• identifying groundswells of tweeted reaction when they occur on a particular theme and identifying the event(s) that are driving it. Our case studies and classifier tests revealed that people do not in general express generic sentiment on Twitter Executive summary about the EU, instead, Twitter was found to be fundamentally a reactive medium; a tweet is overwhelmingly a reaction to an event that the tweeter has otherwise encountered – either online or offline, whether through reading mainstream media or being told by a friend. Therefore, it is best used as a way of gaining insight into how people respond to events, rather than as a continuous ‘poll’ of opinion. The closest analogy to the value of insight from Twitter is perhaps not the population level opinion poll, but rather the noise of a throng of energised citizenry talking about a particular event
• using automatic NLP to build algorithmic classifiers, which can filter out tweets that are irrelevant to the theme in question
• flexibly and reactively building bespoke technology around these specific events to listen to the digital voices – what they are saying and the attitudes, hopes, fears and priorities that they carry with them at scale and speed
• situating these attitudes within the background of the events that were occurring, the media reportage that covered them, and the public discussions that were being carried out
What are digital voices saying?
Using this method, we found a number of specific features about tweets relating to the EU:
The silent majority ‘reaction’ phenomenon
While the general consensus in the UK is that the population is broadly hostile to the European Court of Human Rights (ECHR), it is of note that the response following the Cameron suggestion about leaving the ECHR led to a groundswell of hostile criticism. Even when it came to a very unpopular ruling – preventing the UK from deporting Abu Qatada – most Twitter users rallied around the principle of the ECHR (of 1,344 attitudinal tweets about this decision, 1,181 were classified as pro-ECHR and 163 negative).
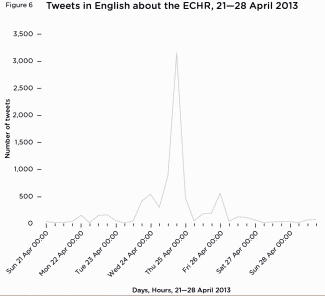
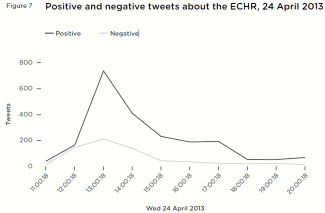
Commission events are a good opportunity to gauge general views
There is clearly a significant surge in activity surrounding major European events, such as summits – they are news stories in themselves. Rather than being based on a single news story (such as the other data sets) there was a significant number of tweets about the summit, which was an occasion for people to bring their own, related topics of concern to the table.
Variation across countries
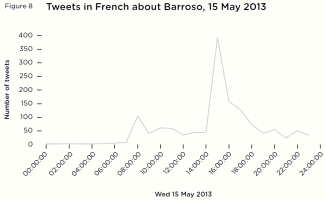
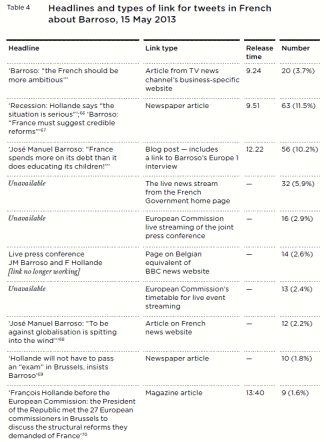
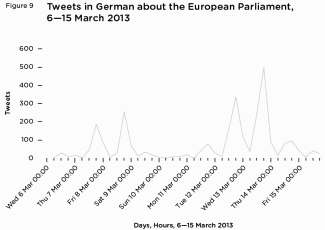
By listening to how people on Twitter reacted to certain events rather than as a continuous whole, they tell a story of users responding to each EU-related case separately and on broad national distinctions. French tweeters thought the European Central Bank was ‘strangling’ Cyprus, while German tweeters continued to worry about Germany’s place in the Eurozone. Both British and French tweeters broadly applauded the ECHR over their own national governments, but French tweeters did not like Barroso’s incendiary admonishments of Hollande and France.
Discussion: Twitter as a source of attitudinal data
Digital observation has considerable strengths and weaknesses compared with conventional approaches of studying attitudes. It is able to leverage more data about people than ever before, with hardly any delay and at very little cost. On the other hand, it uses new, unfamiliar technologies to measure new digital worlds, all of which are not well understood, producing event-specific, ungeneralisable insights that are very different from what has up to this point been produced by attitudinal research in the social sciences. Based on our research, we consider the following strengths and weaknesses to be most significant.
Strengths
Very large data sets available
Twitter data sets are ‘social big data’. The size of the data set gathered even for this pilot is far larger than comparative data sets gathered through conventional polling, interviewing and surveying techniques. Digital observation radically widens the number of voices that can routinely be listened to.
Real-time insight
Relevant tweets are collected almost immediately after they are posted. Digital observation, using automated technologies, draws meaning from these data very quickly after collection. It is therefore possible to understand attitudes about an event as the event happens, and as the public debate evolves. This is perhaps the most important distinction between digital observation and other ways of researching attitudes. Discerning real-time attitudes is a valuable power for institutions to have. It allows them to be agile, and react quickly to groundswells of anger, support or criticism quickly enough to influence the underlying developments and events that drive these attitudes.
‘In conversation’: listening rather than asking removes observation bias
A well-known weakness in most attitudinal research is that data are collected in ‘non-real world’ settings. Most ways of gathering attitudes require a researcher intervening in someone’s life – asking them questions, and recording what they say. This introduces ‘observation effects’, which change the attitudes expressed and views offered in a number of ways. [3] Digital observation avoids these unwanted distortions by listening to digital voices as they rise, naturally, on social media platforms.
Cheap
Attitudinal research is often expensive. It is expensive to employ interviewers and to manage and incentivise panels of participants, to mail surveys to thousands of people and to hire rooms, technology and people to conduct focus groups. Digital observation is very economic in comparison. Acquiring tweets (in certain contexts and quantities) is free and the technology, once in place, can be trained and purposed in a matter of minutes. This lowers the threshold for attitudinal research – many more organisations will be able to listen more often to more conversation that they care about.
Weaknesses
There is no accepted ‘good practice’ for digital observation
Established ways of researching attitudes have long histories of use. This experience has consolidated into a body of good practice – dos and don’ts – which, when followed, ensures the quality of the research. Digital observation does not have a long history of use, or an established collective memory of what works and what does not. It uses new technologies in new ways that are unfamiliar with the social sciences, often with new and important implications for research.
The performance of the technology varies considerably
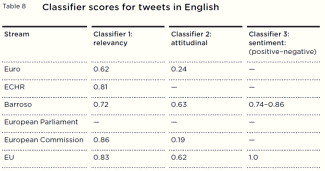
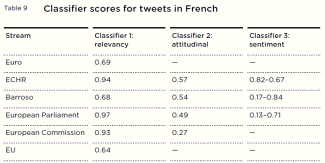
The technology sometimes performed very successfully, and at other times very poorly. In the research, the best performing classifiers were almost always correct, and the worst performing classifiers performed no better than chance. The performance of classifiers depends on the context of the task. We found that generic, long-term classifiers performed inaccurately. Language use – the kinds of words used and the meanings these words have – changes quickly on Twitter. Language is specific to a particular conversation at a particular time. Automated algorithms struggled to find generic meaning accurately independent of a particular event or discussion, and became drastically less accurate over a long period of time. However, bespoke short-term classifiers did well and proved to be able to reliably discern meaning, when trained on a specific event, at a specific time, and in a way that reflects the data. Classifiers performed best when making distinctions that reflected the data at a particular point. There are also other difficulties for classifiers. Non-literal language use, such as sarcasm, pastiche, slang and spoofs, are found to be common on social media. The ‘real’ rather than ironic meaning of these kinds of uses of language are inherently contextual and difficult to deduce via shallow automated analyses.
Sampling: the tweets that are gathered may systemically differ from those that are not
Data are acquired through Twitter by being matched to keywords. The pilots showed that these keywords can produce different kinds of problems – sometimes they are over-inclusive (and collect tweets on other, irrelevant topics), and sometimes they are under-inclusive (and miss relevant tweets). In both these ways, keyword matching is inherently prone to systemic bias – so data collected, and therefore the conclusions drawn, are affected in a non-random way by the search terms employed.
Insights from digital observation can be difficult to generalise
The power of much attitudinal research is that it creates representative data sets that allow for generalisations beyond the group that was actually asked – to age group, area, the country or even the world. Making these generalisations when using Twitter as a source of attitudinal data is difficult because of a problem of representativeness. Twitter users do not demographically represent wider populations: data are collected based on conversations rather than demographic details of a participant. Moreover, collected tweets often do not represent Twitter users. Tweets, in general, are produced by a small number of high-volume ‘power-users’. Compounding this problem, ‘power-users’ are sometimes automated, ‘bot’, fake, official or campaign accounts. Moreover, Twitter is a new social space, allowing the growth of a number of digital cultures and sub-cultures with distinct norms, ways of transacting and speaking and also a new communications medium whose format powerfully influences what is said and meant. The pace with which this context evolves and changes makes the meaning of tweets often unclear or ambiguous.
Recommendations and ways forward
Twitter has become an extremely significant venue for public debate and discussion. Increasingly, it is an important way for citizens to express their attitudes on a range of subjects, including the European project. We recommend that representative organisations examine ways to listen and respond to these digital voices:
Investigate digital observatories
Organisations, especially representative institutions, now have the opportunity to listen cheaply to attitudes expressed on Twitter that matter to them. They should consider establishing digital observatories that are able to identify, collect and listen to digital voices, and establish ways for them be reflected appropriately in how the organisation behaves, the decisions it makes and the priorities it has. Digital observatories, constantly producing real-time information on how people are receiving and talking about events that are happening, could be transformative in demonstrating how organisations relate to wider societies. Just because it is possible to collect social media data does not mean it should be done. Digital observatories should be predicated on public understanding and openness about how they work; and conducted according to strict ethical principles for the collection analysis and use of data. This type of research should not replace existing methods of research, but supplement it.
The EU must adopt a leadership role on how to listen to citizens ethically and robustly
Increasingly, politics is moving online, enabling people to express opinions, politicians to mobilise voters, and anyone to form parties and movements. This opens new roles and opportunities for research to be powerful and useful: to rework communication campaigns that are misunderstood; to delay or halt policy roll-outs that have unintended and unforeseen consequences; and more broadly to allow those in democratic institutions to perceive, react to and represent views during the time when they most matter – as they are expressed. However, as a new field, this also creates ethical risks and dangers of poor research methods. To be a leader in the democratic governance and representation of an increasingly digital world, the EU must stake out leadership in the ethical and effective exploitation of these new technologies, grasping the opportunities they now offer.
Nine principles for social media research
Our ability to understand Twitter as a source of attitudes is nascent. Many of the tools that can handle large numbers of tweets have come from the computer science departments of academia, and the public relations and advertising industries. Their up-take within the sociological, psychological and anthropological disciplines has been slower, and new technologies have often not been reconciled with the values and principles of conventional attitudinal research.
It is necessary to arrive at a new discipline capable of turning social media into social meaning. This pilot demonstrated the strength of combining human and technological analysis, built around a specific event as it happens.
For this to be realised, we recommend the following nine principles for undertaking high quality social media research. They are designed for researchers, advocacy groups and others interested in understanding society, as a set of techniques approaches and methods for how to make the best use of these techniques, and turn the potential of listening to the digital voices into something useful and valuable:
1 Beware the numbers game and ‘sentiment analysis software’ – this will not always deliver the best results and can be misleading
Size is not everything. While there is a burgeoning industry in analysing social media, very large amounts of data often hide sociologically invalid modes of collection and analysis. This is most important for the most popular way of analysing social media content ‘sentiment analysis’, which breaks conversations into ‘positive’, ‘negative’ and ‘neutral’ categories. This kind of analysis often uses NLP in ways that our pilot found unlikely to be successful – generic, standardised, operating over a long period of time and not related to a particular event or conversation.
2 Digital observation can complement existing polling data, but not replace them
It is therefore necessary to use a new approach to ‘attitudes’ that reacts to events in real time. Traditional, representative polling data still remain an extremely powerful way to ascertain attitudinal data, especially across large populations. It is based on tried and tested methods of randomised sampling and questionnaire design. Twitter data are of a different nature – dynamic, unstructured and event-driven. They should be viewed as a complement to, rather than replacement for, traditional polling.
3 Look for ways to mix qualitative and quantitative, automated and manual methods
Automated techniques are only able to classify social media data into one of a small number of categories at a certain (limited) level of accuracy for each message. They are a good first way to tackle scales of data that would otherwise be overwhelming. Manual analysis is therefore almost always a useful and important component; in this report it is used to look more closely at a small number of randomly selected pieces of data drawn from a number of these categories. In scenarios when a deeper and subtler view of the social media data is required, the random selection of social media information can be drawn from a data pool, and sorted manually by an analyst into different categories of meaning.
4 Involve human analyst and subject matter expertise at every step
It is vital that attempts to collect and analyse attitudinal ‘big data’ is guided by an understanding of what is to be studied: how people express themselves, the languages that are used, the contexts – social and political – that attitudes are expressed in, and the issues that they are expressed about. Analysts who understand the issues and controversies that surround the EU are therefore vital in order to contextualise and explain the attitudes that are found on Twitter, and to help build the methods that are used to find and collect these attitudes.
5 Beyond the ‘black box’ – new big data technologies must be presented in a way that non-specialists can understand
Non-technical specialists are often the end-users of the research, and it is vital that the technology, however sophisticated, is explained in a way that clearly lays out how it was used and what the implications of its use are. This means clarity and detail must be provided about how the search terms were constructed and why, what type of data access terms were used, how well the classifier performed against a human analyst, and what the likely biases in the data were.
6 Use new technologies in contexts where they work. NLP classifiers should be bespoke, not generic and driven by the data rather than predetermined
Overall, NLP classifiers seem to perform best when they are bespoke and event-driven rather than generic. When categories to sort and organise data are applied a priori, there is a danger that they reflect the preconceptions of the analyst rather than the evidence. It is important that classifiers should be constructed to organise data along lines that reflect the data rather than the researcher’s expectations. This is consistent with a well-known sociological method called grounded theory. [4]
7 New roving, changeable sampling techniques
The collection of systemically biased data from Twitter is far from easy. The search terms that are used are vulnerable to Twitter’s viral, short-term surging variations in the way that language is used to describe any particular topic, so keyword searches are liable to result in bias and/or incomplete data sets. Therefore, development is needed to improve ways of sampling in a more coherent and repeatable way.
8 From metrics to meaning
Numbers and measurements alone cannot talk for themselves, and do not represent meaningful insight that can be acted on. It is here, in the ability to translate measurements into insight and understanding that can be acted on, that most work is required. Findings from digital observation must be intensively contextualised within broader bodies of work in order to draw out causalities and more general insights.
9 Apply a strict ethical approach at every step
Researching people entails moral hazard. Research can harm the individual participants involved or more broadly the society from which they are drawn. Ethical codes of conduct are used by researchers to minimise these harms, and balance them against the social benefits of the research. In the UK, the standard best practice for research ethics is the ethical framework of the Economic and Social Research Council (ESRC), which is made up of six principles. [5] It is unclear, however, how these can be applied for the mass collection of social media data. At the time of this writing, no official frameworks on internet research ethics have been adopted at any national or international level.[6] Social media research of this kind is a new field, and the extent to which (and how) these ethical guidelines apply practically to research taking place on social media is unclear. We consider that the two most important principles to consider for this type of work are whether informed consent is necessary to reuse the Twitter data that we collected, and whether there are any possible harms to participants in republishing their tweets that must be measured, managed and minimised. Researchers must bear these considerations in mind at all times, and not assume that because data are available it is necessarily ethical to access and use them. We therefore suggest that all academic research work that involves collecting social media data relating to individuals should be subject to ethical review boards.