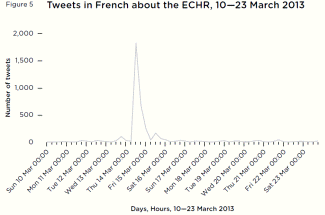
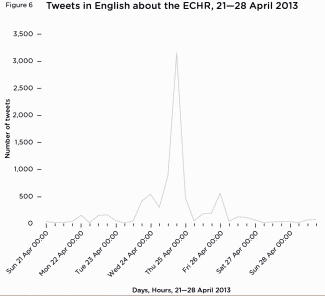
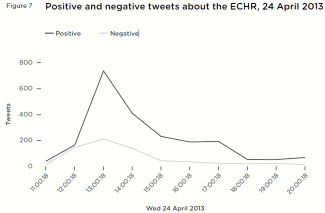
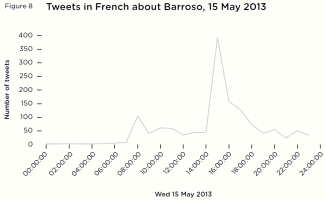
The difference in abuse between the sexes online isn’t in the amount but the type. Data shows men get more hate, while women say they get it because they’re women.
by The Daily Beast
September 4, 2014
NOTICE: THIS WORK MAY BE PROTECTED BY COPYRIGHT
YOU ARE REQUIRED TO READ THE COPYRIGHT NOTICE AT THIS LINK BEFORE YOU READ THE FOLLOWING WORK, THAT IS AVAILABLE SOLELY FOR PRIVATE STUDY, SCHOLARSHIP OR RESEARCH PURSUANT TO 17 U.S.C. SECTION 107 AND 108. IN THE EVENT THAT THE LIBRARY DETERMINES THAT UNLAWFUL COPYING OF THIS WORK HAS OCCURRED, THE LIBRARY HAS THE RIGHT TO BLOCK THE I.P. ADDRESS AT WHICH THE UNLAWFUL COPYING APPEARED TO HAVE OCCURRED. THANK YOU FOR RESPECTING THE RIGHTS OF COPYRIGHT OWNERS.

The issue of Internet misogyny has received a great deal of attention in recent weeks, between the feminist website Jezebel battling rape GIFs repeatedly posted to their comments section and videogame critic Anita Sarkeesian having to leave her home after a series of Twitter threats that included her home address. There is a common assumption that the targets of such vile behavior are overwhelmingly women who are abused because they are women—to the point where “women aren’t welcome on the Internet,” as Amanda Hess argued in a widely discussed article in Pacific Standard magazine this year. Reviewing women’s online tribulations in the last month in The Daily Beast, Samantha Allen asks, “Will the Internet ever be safe for women?”
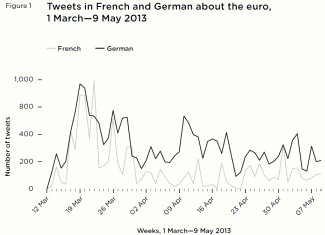
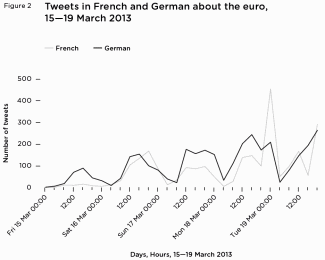
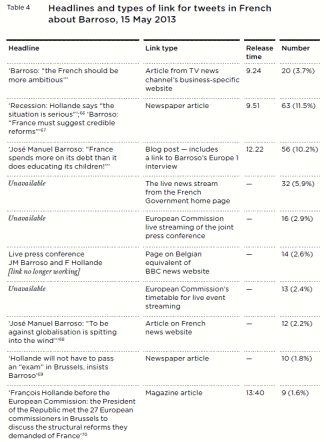
At the same time, there was little reaction to a report contradicting the narrative that male public figures get considerably less Twitter abuse than their female counterparts. While the study, conducted by the British think tank Demos, was limited to a fairly small sample of British celebrities, journalists and politicians whose Twitter timelines were tracked over a two-week period, its findings are nonetheless interesting. [*] On the whole, 2.5 percent of the tweets sent to the men but fewer than 1 percent of those sent to women were classified as abusive. Male politicians fared especially badly, receiving more than six times as much abuse as female politicians. (emphasis not in original)
Current ways of researching society cannot handle these kinds of data in the volumes that are now produced. While there is a burgeoning industry in applying new computational techniques to try to analyse social media data, it can be misleading, and often hides sociologically invalid modes of collection and analysis. This is most important for the most popular way of analysing social media content ‘sentiment analysis’, which breaks conversations into ‘positive’, ‘negative’ and ‘neutral’ categories. This kind of analysis often uses natural language processing (NLP) in ways that our pilot found unlikely to be successful – generic, standardised, operating over a long period of time, and not related or trained to a particular event or conversation....
Digital observation has considerable strengths and weaknesses compared with conventional approaches of studying attitudes. It is able to leverage more data about people than ever before, with hardly any delay and at very little cost. On the other hand, it uses new, unfamiliar technologies to measure new digital worlds, all of which are not well understood, producing event-specific, ungeneralisable insights that are very different from what has up to this point been produced by attitudinal research in the social sciences ...
Weaknesses
There is no accepted ‘good practice’ for digital observation
Established ways of researching attitudes have long histories of use. This experience has consolidated into a body of good practice – dos and don’ts – which, when followed, ensures the quality of the research. Digital observation does not have a long history of use, or an established collective memory of what works and what does not. It uses new technologies in new ways that are unfamiliar with the social sciences, often with new and important implications for research.
The performance of the technology varies considerably
The technology sometimes performed very successfully, and at other times very poorly. In the research, the best performing classifiers were almost always correct, and the worst performing classifiers performed no better than chance. The performance of classifiers depends on the context of the task. We found that generic, long-term classifiers performed inaccurately. Language use – the kinds of words used and the meanings these words have – changes quickly on Twitter. Language is specific to a particular conversation at a particular time. Automated algorithms struggled to find generic meaning accurately independent of a particular event or discussion, and became drastically less accurate over a long period of time. However, bespoke short-term classifiers did well and proved to be able to reliably discern meaning, when trained on a specific event, at a specific time, and in a way that reflects the data. Classifiers performed best when making distinctions that reflected the data at a particular point. There are also other difficulties for classifiers. Non-literal language use, such as sarcasm, pastiche, slang and spoofs, are found to be common on social media. The ‘real’ rather than ironic meaning of these kinds of uses of language are inherently contextual and difficult to deduce via shallow automated analyses.
Sampling: the tweets that are gathered may systemically differ from those that are not
Data are acquired through Twitter by being matched to keywords. The pilots showed that these keywords can produce different kinds of problems – sometimes they are over-inclusive (and collect tweets on other, irrelevant topics), and sometimes they are under-inclusive (and miss relevant tweets). In both these ways, keyword matching is inherently prone to systemic bias – so data collected, and therefore the conclusions drawn, are affected in a non-random way by the search terms employed.
Insights from digital observation can be difficult to generalise
The power of much attitudinal research is that it creates representative data sets that allow for generalisations beyond the group that was actually asked – to age group, area, the country or even the world. Making these generalisations when using Twitter as a source of attitudinal data is difficult because of a problem of representativeness. Twitter users do not demographically represent wider populations: data are collected based on conversations rather than demographic details of a participant. Moreover, collected tweets often do not represent Twitter users. Tweets, in general, are produced by a small number of high-volume ‘power-users’. Compounding this problem, ‘power-users’ are sometimes automated, ‘bot’, fake, official or campaign accounts. Moreover, Twitter is a new social space, allowing the growth of a number of digital cultures and sub-cultures with distinct norms, ways of transacting and speaking and also a new communications medium whose format powerfully influences what is said and meant. The pace with which this context evolves and changes makes the meaning of tweets often unclear or ambiguous.
-- Vox Digitas, by Demos
The only category in which women got more Twitter abuse than men was journalism: abusive messages accounted for more than 5 percent of the tweets sent to the female journalists and TV presenters in the study and fewer than 2 percent of the ones sent to the male journalists. (However, the most abused male journalist in the sample, controversial ex-CNN host Piers Morgan, was counted as a “celebrity” rather than a journalist; otherwise, he would have single-handedly raised the proportion of abusive tweets to male journalists to almost 6 percent of the total.) While about three-quarters of the offenders were men, about 40 percent of the abusive tweets to women were sent by other women.
Are women really singled out for abuse on the Internet—or is it more the case that Internet abuse of women, at least when committed by men, is singled out for special concern and opprobrium? Many feminists would argue that there are good reasons to treat it differently. Sexual slurs toward women evoke the threat of real-life sexual violence; they are also perceived as intended to “put a woman in her place” and tell her that her opinion is worthless because she is a woman. (A sexual slur toward a man is considered just a personal insult.) But the double standard also has overtones of traditional chivalry which views women as more delicate and deserving of consideration—while nastiness toward men is treated simply a part of the rough-and-tumble of public life, to be taken in stride and shrugged off.
The Demos report on Twitter abuse toward public figures is only one of several studies that cast doubt on the assumption that the Internet is a hotbed of male hostility toward women. In an earlier Demos analysis, women on Twitter were almost as likely as men to use “gendered” derogatory language.
A survey of Internet users conducted by the Pew Research Center last year found that 13 percent of female respondents and 11 percent of male respondents said they had been harassed or stalked online. (While Hess’s Pacific Standard article drew on that survey to note that “5 percent of women who used the Internet said ‘something happened online’ that led them into ‘physical danger,’” it made no mention of the fact that 3 percent of the men also reported such an experience.)
If women are unsafe or unwelcome on the Internet, it’s hardly borne out by the numbers.
Women and men also had very similar concerns about Internet privacy and security; while more women than men (77 vs. 61 percent) had changed their privacy settings to restrict some people from seeing their activities, women were only marginally more likely to have blocked or unfriended someone in the social media or to have asked someone to remove online information posted about them.
The most dramatic claim of pervasive online misogyny—that Internet accounts with feminine usernames get an average of 100 threatening or sexually abusive messages a day, to just four for male usernames—comes from a 2006 study conducted in Internet relay chatrooms, hardly typical of today’s social media use. [Assessing the Attack Threat Due to IRC Channels, by R. Meyer, Dept. of Electr. & Comput. Eng., Maryland Univ., College Park, MD; Michel Cukier] Women also account for 72 percent of those reporting harassment incidents to the volunteer organization Working to Halt Online Abuse. But this is a self-selected sample, and the disparity may well reflect the fact that it’s more socially acceptable for women to seek help when they are harassed. (It should also be noted that the website’s annual rate of complaints from women is fewer than 300—obviously a cause for concern, but hardly an epidemic level.)
If women are unsafe or unwelcome on the Internet, it’s hardly borne out by the numbers. Women consistently use social networking sites more than men, outnumbering men on Facebook by about 10 percentage points; while there is conflicting evidence on whether Twitter has shifted from a majority-female demographic to a more male-skewed one, the likely reasons include the growing popularity of other platforms such as Pinterest and Tumblr along women.
Of course, none of this diminishes the deeply disturbing fact of female journalists, bloggers, and activists—Hess among them—who have been targets of threats to themselves or their families. But are men really immune from such attacks? One blogpost (civilly) critical of Sarkeesian and her supporters offers a fully sourced compilation of online comments wishing death, rape, mutilation and deadly diseases upon Jack Thompson, an activist critical of violent and sexual content in videogames—as well as death threats directed at male videogame developers who ran afoul of their fans. Meanwhile, role-playing game designer James Desborough claims to have been viciously threatened for defending the use of sexual violence as a plot element in games. And film blogger Alex Sandell (Juicy Cerebellum) has described receiving not only a deluge of hate mail but threatening phone calls—sometimes in the middle of the night, and sometimes made to his relatives—after writing negative reviews of the first two Lord of the Rings movies.
In the political sphere, several conservative male writers and activists have been targeted for rape and death threats, with their phone numbers publicly posted, after producing a documentary critical of the Occupy movement. Right-wing bloggers involved in the bizarre war with leftist activist Brett Kimberlin that David Weigel recently chronicled in The Daily Beast have faced scary cyber-harassment from some of Kimberlin’s supporters, including graphic fantasies of violent revenge, lurid sexual slurs, and accusations of child pornography. (Particularly disturbing examples are documented in a blogpost by First Amendment advocate Ken White.) On the other side, Charles Johnson, who runs the blog Little Green Footballs, relocated to a gated community because of threats he received after breaking with the right and embracing more liberal politics.
HE SAID JEHOVAH! HE SAID JEHOVAH!
BY KEN WHITE
SEPTEMBER 16, 2011
As we've discussed many times before, our friends in Canada have a government with very strong opinions about what opinions are "acceptable" — meaning what opinions may be uttered without prosecution, fines, cease-and-desist orders, and reeducation. It's not to American tastes to create vast bureaucracies with the power to regulate and punish speech based on vague guidelines, but Canada is a sovereign nation, and can do what it wants.
Pity poor Professor Cameron Johnston at York University. He was just trying to make this fundamentally Canadian concept clear to the students in the class he was teaching by giving examples of unacceptable opinions. Really, reminding them that some opinions are unacceptable was, in the Canadian context, an act of great patriotism, akin to starting an American lecture with the Pledge of Allegiance and possibly a barbecue. In the course of being so very Canadian, Prof. Johnston mentioned that the sentiment "all Jews should be sterilized" was "unacceptable."
Regrettably, Professor Johnston doesn't get it.
See, it doesn't matter that he uttered the words in a context — the context of identifying the sort of opinions that are unacceptable to Canada. He still uttered them.
By uttering the words, Prof. Johnston committed speechcrime. That's a strict liability crime; intent is irrelevant. Moreover, in thinking that he could utter a series of offensive words by putting them into a specific disapproving and pedagogical context, Prof. Johnston committed a hate crime against the Moron-Canadian community, which is too stupid to grasp context, and the Entitled-Canadian community, which believes that it is un-Canadian to require them to pay close enough attention to follow context. Prof. Johnston knew or should have known that his class of 450 people would include members of the Moron-Canadian and Entitled-Canadian community.
And indeed it did — in the form of Sarah Grunfeld, a member of the Moron-Insipid-Entitled-Canadian community. Sarah Grunfeld was outraged to hear, sort of, that her professor thought that all Jews should be sterilized, and started quite a stir, complaining to York University officials and various community members. Tumult and inquisition ensued. The Canadian media acted in an appallingly un-Canadian manner, focusing on the so-called "context" of Professor Johnson's words and the utterly irrelevant detail that he was Jewish. Grunfeld, raised by her actions into a position of leadership in the Entitled-, Insipid-, and Moron-Canadian communities, did her best to set them back on the path of right thinking:Grunfeld said Tuesday she may have misunderstood the context and intent of Johnston’s remarks, but that fact is insignificant.
“The words, ‘Jews should be sterilized’ still came out of his mouth, so regardless of the context I still think that’s pretty serious.”
Grunfeld also expressed skepticism that Johnston was in fact Jewish.
Asked directly by a reporter whether she believes Johnston is lying, she was unclear.
“Whether he is or is not, no one will know,” she said. “. . . Maybe he thought because he is Jewish he can talk smack about other Jews.”
Grunfeld demonstrates that with proper accommodation, Moron-Canadian students are able to learn the most important lessons that modern universities offer, such as the lesson that there is no objective reality. Is the person-object-construct we call "Professor Johnston" Jewish? What a childish question, reflecting a retrograde, linear belief system. Whatever "Professor Johnson" or other social constructs like "The Center for Israel and Jewish Affairs" might say, whether the "Johnston" person-object is "Jewish" depends on the shifting perceptions of people like Grunfeld and on advanced scholarship by deep thinkers.
Shockingly, some Jews in Canada are contributing to the continuing wordcrime, failing to cherish Canadian values:In response, Sheldon Goodman, the GTA Co-Chair of the Centre for Israel and Jewish Affairs issued the following statement:
“Upon hearing of this incident, we immediately contacted York University as well as Professor Johnston directly. While York is currently looking into the matter, it appears that a very unfortunate misunderstanding has taken place. We believe Professor Johnston’s use of an abhorrent statement was intended to demonstrate that some opinions are simply not legitimate. This point was, without ill intentions, taken out of context and circulated in the Jewish community.
“Professor Johnston, himself a member of the Jewish community, may regret his wording but should not see his reputation tarnished. This event is an appropriate reminder that great caution must be exercised before concluding a statement or action is anti-Semitic.”
Sheldon "Goodman" doesn't get it. He's focused on "context." He's using "logic" and "inquiry." He might as well come right out and label Sarah Grunfeld and all the members of her dull-witted inattentive community as second-class citizens. Fortunately there are other Jewish-Canadians who are better assimilated into Canadian values. B'nai Brith of Canada, which has a record of supporting Canadian values about speech, is fully supporting the Moron-Canadian community by running Sarah Grunfeld's statement in full. In that statement, she speaks out bravely against all the bigots who wrongfully demanded her to absorb hate-concepts like context, comprehension, and caution:I stand by my initial concern brought to the University’s attention immediately after the incident that when Professor Cameron Johnston made the abhorrent statement in his class that all Jews should be sterilized, he failed to qualify the statement clearly as an unacceptable opinion held by others. His delivery of this statement, made in a class of 450 impressionable students, was offensive to me and to others in the room.
I have since been grossly misquoted and ridiculed by the media, and attempts have been made to assign blame to me with the false claim that I simply “misheard” or “half heard” what was said. Meanwhile, the professor has not been called to account in any way for his “miscommunication”.
But Sarah's not done. Showing great insight far beyond her years and apparent natural abilities, she identifies what the real crime is here: that people — people like her — will be deterred from making careless, stupid accusations of racism if those accusations are actually subjected to scrutiny, and if the accusers are burdened with hateful responsibility for paying attention to what's going on around them:It has been a very painful experience for me to see how the university has closed ranks and reneged on its assurances to me. I understand that there may have been a miscommunication, but any miscommunication was on the part of the professor, not me. The media has been complicit in allowing a false interpretation of my actions to be circulated widely, which can only have a chilling effect on the ability of students to have any kind of a voice on campus.
Well said. There ought to be a government inquiry — perhaps by Jennifer Lynch — into whether universities and the media are chilling stupid people from being stupid.
Meanwhile, if Sarah Grunfeld feels that Canada is a cold and barren place that refuses to celebrate her differences, she should consider coming here to America. Sure, we don't have Human Rights Councils like Canada. But there are signs that our universities and their administrators are coming around to Sarah's way of "thinking," and doing what they can to protect the moron community. At Brandeis University, Professor Donald Hindley uttered the word "wetback" in the course of criticizing people who use it; the 50-year teaching veteran was found guilty of racial harassment and forced to admit an ideology-monitor to his class. At Widener University School of Law, administrators are defying a hearing panel that cleared professor Lawrence Connell, and insisting that he be punished for using the term "black folks" in class and using the name of an administrator in an exam hypothetical.
And surely I need not offer you links to establish that modern America is, in fact, very welcoming to morons.
Come on down, Sarah. You've got lots of friends here.
One male victim of cyberstalking, British expatriate novelist James Lasdun, told his story in the 2013 memoir, Give Me Everything You Have: On Being Stalked. Lasdun’s stalker, a former creative-writing student whose romantic overtures he had rejected, not only barraged him with abusive messages but emailed his colleagues accusing him of stealing her work, preying on female students, and even setting her up to be raped; she posted similar slanders on websites including Amazon.com and Wikipedia. But an experience like Lasdun’s gets no political sympathy; indeed, the review in The New Yorker chided him for failing to admit his “crush” on the woman and his role in leading her on.
Online abuse and trolling that doesn’t rise to the level of stalking or threats can still be toxic. When directed at women, such abuse can certainly take misogynist forms (whether because the troll actually hates women or because it’s the surest way to bait and provoke his—or her—target). But it can also come from feminists—both in internecine feminist wars, discussed recently by critics such as journalist Michelle Goldberg in The Nation, and in attacks on female dissenters. (Writer and blogger Susannah Breslin faced a particularly vicious backlash a few years ago after she criticized the then-new trend of “trigger warnings” in feminist media.) And plenty of time, such abuse is directed at men, in male-specific ways that we rarely think of as “gendered”: from questioning someone’s manhood to attacking his “male privilege,” from taunts about penis size to accusations of pedophilia, rape, or pro-rapist sympathies. The torrent of sometimes violent invective heaped last year at Dr. Phil McGraw after his tweet asking if it’s OK to have sex with a drunk girl was seen as righteous outrage against a “rape apologist” question, not online abuse.
Often, in our commitment to free speech, we have been too willing to accept toxic behavior on the Internet. Just because abusive speech is protected by the First Amendment doesn’t mean that private websites should give it a platform. There is, too, a very real need for law enforcement to catch up with technology and offer meaningful solutions to cyberstalking and threats. However, the war on online abuse, particularly with the agenda of making the Internet safe for women, has its own perils.
There is the obvious danger of censoring legitimate speech. In Canada right now, a middle-aged designer named Gregory Elliott is on trial for criminal harassment for sending non-sexual, non-threatening, but argumentative unwelcome tweets to feminist activist Stephanie Guthrie. But there is also the danger of perpetuating women’s vulnerabilities in the name of protecting them. In her analysis of videogames, Sarkeesian has been particularly critical of damsel-in-distress stereotypes and casual “depictions of female victimhood.” Yet we bolster the same stereotypes when we focus on nasty things said to women while trivializing threats against men even though men are much more likely to be victims of violence by strangers.
As long as the Internet exists, there will be rude, nasty, and unstable people on it—and sometimes, you will be attacked, especially if you write and speak on controversial subjects. We need a better middle ground between telling victims of harassment to grow a thick skin, and telling people they have a right to be shielded from all un-pleasantries. As we search for that middle ground, we should beware of paternalism based on the mistaken view that Internet nastiness is a particular problem for women.
______________
[Librarian's Note: * It would have been equally reasonable to derive the meaningless fact from this data that elite men suffered greater rates of testicular cancer than "elite women," precisely because so very few people fit the category of "female political elite." Besides the Queen and her progeny, of course.]